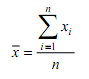BAB 6 DISTRIBUSI NORMAL, T DAN F
A. Karakteristik Distribusi Probabilitas Normal
Distribusi probabilitas normal dan kurva
normal telah dikembangkan oleh DeMoivre (1733) dan Gauss (1777 – 1855)
dengan menurunkan persamaan matematis dan kurva normalnya. Oleh sebab
itu, kurva normal sering juga disebut kurva Gauss.

Beberapa karakteristik dari distribusi probabilitas dan kurva normal adalah:
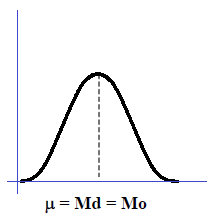
- Kurva berbentuk genta atau lonceng dan memiliki satu puncak yang terletak di tengah. Nilai rata-rata hitung (µ) = median (Md) = modus (Mo). Nilai µ = Md = Mo yang berada di tengah membelah kurva menjadi dua bagian yaitu setengah di bawah nilai µ = Md = Mo dan setengah di atas nilai µ = Md = Mo.
- Distribusi probabilitas dan kurva normal berbentuk kurva simetris dengan rata-rata hitungnya (µ).
- Distribusi probabilitas dan kurva normal bersifat asimptotis.
- Kurva mencapai puncak pada saat X = µ.
- Luas daerah di bawah kurva normal adalah 1; ½ di sisi kanan nilai tengah dan ½ di sisi kiri.
Bila X suatu pengubah acak normal dengan nilai tengah μ, dan standar deviasi σ, maka persamaan kurva normalnya adalah:

B. Jenis-jenis Distribusi Probabilitas Normal
- Distribusi Probabilitas dan Kurva Normal dengan μ dan σ Berbeda
Bentuk distribusi probabilitas dan kurva
normal dengan nilai tengah sama dan standar deviasi yang berbeda, adalah
bentuk leptokurtic, platykurtik dan mesokurtik. Kurva normal tersebut
mempunyai μ = Md = Mo yang sama, namun mempunyai σ berbeda. Semakin
besar σ, maka kurva semakin pendek dan semakin tinggi
nilai σ, maka semakin runcing. Oleh sebab itu, σ tinggi cenderung
menjadi platykurtik dan σ rendah menjadi leptokurtik. Nilai σ yang
tinggi menunjukkan bahwa nilai data semakin menyebar dari nilai
tengahnya (μ). Apabila σ rendah, maka nilai semakin mengelompok pada
nilai tengahnya.

- Distribusi Probabilitas dan Kurva Normal dengan μ Berbeda dan σ Sama
Bentuk distribusi probabilitas dan kurva normal dengan μ berbeda dan σ sama mempunyai jarak antara
kurva yang berbeda, namun bentuk kurva tetap sama. Hal demikian bisa
terjadi karena kemampuan antar populasi berbeda, namun setiap populasi
mempunyai keragaman yang hampir sama.

- Distribusi Probabilitas dan Kurva Normal dengan μ dan σ Berbeda
Distribusi kurva normal dengan μ dan σ berbeda. Kurva ini mempunyai titik pusat yang berbeda pada sumbu mendatar dan bentuk kurva berbeda karena mempunyai standar deviasi yang berbeda.

C. Distribusi Probabilitas Normal Baku
- Distribusi normal baku adalah distribusi probabilitas acak normal dengan nilai tengah nol dan simpangan baku 1.
- Seringkali disebut dengan distribusi z.
- Hal yang perlu dilakukan dalam rangka distribusi probabilitas normal baku adalah mengubah atau membakukan distribusi aktual dalam bentuk distribusi norma baku yang dikenal dengan nilai Z atau skor Z
- Nilai Z adalah jarak yang berbeda antara sebuah nilai X yang dipilih dari ratarata μ, dibagi dengan standar deviasinya, σ.

Z = Skor Z atau nilai normal baku
X = Nilai dari suatu pengamatan atau pengukuran
μ= Nilai rata-rata hitung suatu distribusi
σ= Standar deviasi
Contoh Soal:
Rata-rata berat sebuah kotak adalah 283
gram dan standar deviasinya 1,6 gram. Berapakah probabilitas sebuah
kotak dibawah 284,5 gram ?


Transformasi dari X ke Z

Bila nilai X berada di antara X = x1 dan X = x2, maka variabel acak Z akan berada di antara nilai:

Transformasi ini juga mempertahankan luas di bawah kurvanya, artinya:

Misalkan kita memilih 20 saham pada bulan
Mei 2007. Harga saham ke-20 perusahaan tersebut berkisar antara Rp.
2.000 – 2.805 per lembarnya. Berapa probabilitas harga saham antara Rp.
2.500 sampai 2.805 per lembarnya. Diketahui μ = 2.500 sebagai nilai
rata-rata hitung dan standar deviasinya 400.
Z = (X – μ) / σZ1 = (2.500 – 2500) / 400
Z1 = 0 / 400 = 0
Z2 = (2.805 – 2.805) / 400
Z2 = 0.76
D. Luas Daerah Di Bawah Kurva Normal

Kurva setiap distribusi peluang
kontinu atau fungsi padat dibuat sedemikian rupa sehingga luas di bawah
kurva di antara kedua ordinat x = x1 dan x = x2 sama dengan peluang acak
X mendapatkan harga antara x = x1 dan x = x2. Luas di bawah kurva
antara dua ordinat sembarang tergantung pada harga µ dan σ.
Luas antara nilai Z (-1<Z<1) sebesar 68,26% dari jumlah data.
Berapa luas antara Z antara 0 dan sampai Z = 0,76 atau biasa dituis P(0<Z<0,76)?
Dapat dicari dari tabel luas di bawah kurva normal. Nilainya dihasilkan = 0,2764
E. Penerapan Kurva Normal
Contoh Soal 1

PT GS mengklaim rata-rata berat buah
mangga “B” adalah 350 gram dengan standar deviasi 50 gram. Bila berat
mangga mengikuti distribusi normal, berapa probabilitas bahwa berat buah
mangga mencapai kurang dari 250 gram, sehingga akan diprotes oleh
konsumen.

Jawab:
Transformasi ke nilai z
AP(x< 250); P(x=250) = (250-350)/50=-2,00 Jadi P(x<250)=P(z<-2,00)
Lihat pada tabel luas di bawah kurva normal
P(z<-2,00)=0,4772
Luas sebelah kiri nilai tengah adalah
0,5. Oleh sebab itu, nilai daerah yang diarsir menjadi 0,5 –
0,4772=0,0228. Jadi probabilitas di bawah 250 gram adalah 0,0228
(2,28%). Dengan kata lain probabilitas konsumen protes karena berat buah
mangga kurang dari 250 gram adalah 2,28%.
Contoh Soal 2
PT Work Electric, memproduksi Bohlam Lampu yang dapat hidup 900 jam dengan standar deviasi 50 jam. PT Work Electric ingin mengetahui berapa persen produksi pada kisaran antara 800-1.000 jam, sebagai bahan promosi bohlam lampu. Hitung berapa probabilitasnya!

Jawab:
P(800<X<1.000)?
Z2 = (1.000-900)/50 = 2,00
Sehingga luas daerah yang diarsir adalah = 0,4772+0,4772= 0,9544. Jadi P(800<X<1.000) = P(-2,00 < Z<2,00) = 0,9544.
Jadi 95,44% produksi berada pada kisaran 800-1.000 jam. Jadi jika PT Work Electric mengklaim bahwa lampu bohlamnya menyala 800-1.000 jam, mempunyai probabilitas benar 95,44%, sedang sisanya 4,56% harus dipersiapkan untuk garansi.
F. Pendekatan Normal Terhadap Binominal
Apabila kita perhatikan suatu distribusi probabilitas binomial, dengan semakin besarnya nilai n, maka semakin mendekati nilai distribusi normal. Gambar berikut menunjukkan distribusi probabilitas binomial dengan n yang semakin membesar.

Bila nilai X adalah distribusi acak binomial dengan nilai tengah μ = np dan standar deviasi σ = √npq, maka nilai Z untuk distribusi normal adalah:

di mana n >>>> ¥ dan nilai p mendekati 0,5
Faktor Koreksi Kontinuitas
Nilai koreksi kontinuitas adalah sebesar 0,5 yang dikurangkan dan ditambahkan pada data yang diamati. Untuk mengubah pendekatan dari binomial ke normal, memerlukan faktor koreksi, selain syarat binomial terpenuhi: (a) hanya ada dua peristiwa, (b) peristiwa bersifat independen; (c) besar probabilitas sukses dan gagal sama setiap percobaan, (d) data merupakan hasil penghitungan. Menggunakan faktor koreksi yang besarnya 0,5.
Contoh Soal:
Adi merupakan pedagang buah di Tangerang. Setiap hari ia membeli 300 kg buah di Pasar Induk Kramat Jati, Jakarta Timur. Probabilitas buah tersebut laku dijual dalah 80% dan 20% kemungkinan tidak laku dan busuk. Berapa probabilitas buah sebanyak 250 kg laku dan tidak busuk ?
Jawab:
n = 300; probabilitas laku p = 0.8, dan q = 1 – 0.8 = 0.2
Diketahui X = 250, dan dikurangi faktor koreksi 0.5 sehingga X = 250 – 0.5 = 249.5
Dengan demikian nilai Z menjadi:
Z = (249.5 – 240) / 6.93 = 1.37 dan P (Z<1.37) = 0.4147
Jadi probabilitas laku adalah 0.5 + 0.4147 = 0.9147
Dengan kata lain harapan buah laku 250 kg adalah 91.47%
Daftar Pustaka:
Suharyadi, & Purwanto S. K. (2007). Statistika: Untuk Ekonomi dan Keuangan Modern, Edisi 2. Jakarta: Penerbit Salemba Empat.
http://tekdig2011.blogspot.com/2012/05/distribusi-normal.html
http://blog.ub.ac.id/adiarsa/tag/macam-distribusi/
http://asmauna.wordpress.com/tag/binomial/
http://mrfree793.blogspot.com/2012/06/distribusi-normal.html
PT Work Electric, memproduksi Bohlam Lampu yang dapat hidup 900 jam dengan standar deviasi 50 jam. PT Work Electric ingin mengetahui berapa persen produksi pada kisaran antara 800-1.000 jam, sebagai bahan promosi bohlam lampu. Hitung berapa probabilitasnya!

Jawab:
P(800<X<1.000)?
Hitung nilai Z
Z1 = (800-900)/50 = -2,00;Z2 = (1.000-900)/50 = 2,00
Jadi: P(800<X<1.000) =P(-2,00<Z<2,00);
P(-2,00<Z) = 0,4772 dan P(Z>2,00) = 0,4772Sehingga luas daerah yang diarsir adalah = 0,4772+0,4772= 0,9544. Jadi P(800<X<1.000) = P(-2,00 < Z<2,00) = 0,9544.
Jadi 95,44% produksi berada pada kisaran 800-1.000 jam. Jadi jika PT Work Electric mengklaim bahwa lampu bohlamnya menyala 800-1.000 jam, mempunyai probabilitas benar 95,44%, sedang sisanya 4,56% harus dipersiapkan untuk garansi.
F. Pendekatan Normal Terhadap Binominal
Apabila kita perhatikan suatu distribusi probabilitas binomial, dengan semakin besarnya nilai n, maka semakin mendekati nilai distribusi normal. Gambar berikut menunjukkan distribusi probabilitas binomial dengan n yang semakin membesar.

Bila nilai X adalah distribusi acak binomial dengan nilai tengah μ = np dan standar deviasi σ = √npq, maka nilai Z untuk distribusi normal adalah:

di mana n >>>> ¥ dan nilai p mendekati 0,5
Faktor Koreksi Kontinuitas
Nilai koreksi kontinuitas adalah sebesar 0,5 yang dikurangkan dan ditambahkan pada data yang diamati. Untuk mengubah pendekatan dari binomial ke normal, memerlukan faktor koreksi, selain syarat binomial terpenuhi: (a) hanya ada dua peristiwa, (b) peristiwa bersifat independen; (c) besar probabilitas sukses dan gagal sama setiap percobaan, (d) data merupakan hasil penghitungan. Menggunakan faktor koreksi yang besarnya 0,5.
Contoh Soal:
Adi merupakan pedagang buah di Tangerang. Setiap hari ia membeli 300 kg buah di Pasar Induk Kramat Jati, Jakarta Timur. Probabilitas buah tersebut laku dijual dalah 80% dan 20% kemungkinan tidak laku dan busuk. Berapa probabilitas buah sebanyak 250 kg laku dan tidak busuk ?
Jawab:
n = 300; probabilitas laku p = 0.8, dan q = 1 – 0.8 = 0.2
μ = np = 300 x 0.80 = 240
σ = √npq = √300 x 0.80 x 0.20 = 6.93Diketahui X = 250, dan dikurangi faktor koreksi 0.5 sehingga X = 250 – 0.5 = 249.5
Dengan demikian nilai Z menjadi:
Z = (249.5 – 240) / 6.93 = 1.37 dan P (Z<1.37) = 0.4147
Jadi probabilitas laku adalah 0.5 + 0.4147 = 0.9147
Dengan kata lain harapan buah laku 250 kg adalah 91.47%
Daftar Pustaka:
Suharyadi, & Purwanto S. K. (2007). Statistika: Untuk Ekonomi dan Keuangan Modern, Edisi 2. Jakarta: Penerbit Salemba Empat.
http://tekdig2011.blogspot.com/2012/05/distribusi-normal.html
http://blog.ub.ac.id/adiarsa/tag/macam-distribusi/
http://asmauna.wordpress.com/tag/binomial/
http://mrfree793.blogspot.com/2012/06/distribusi-normal.html